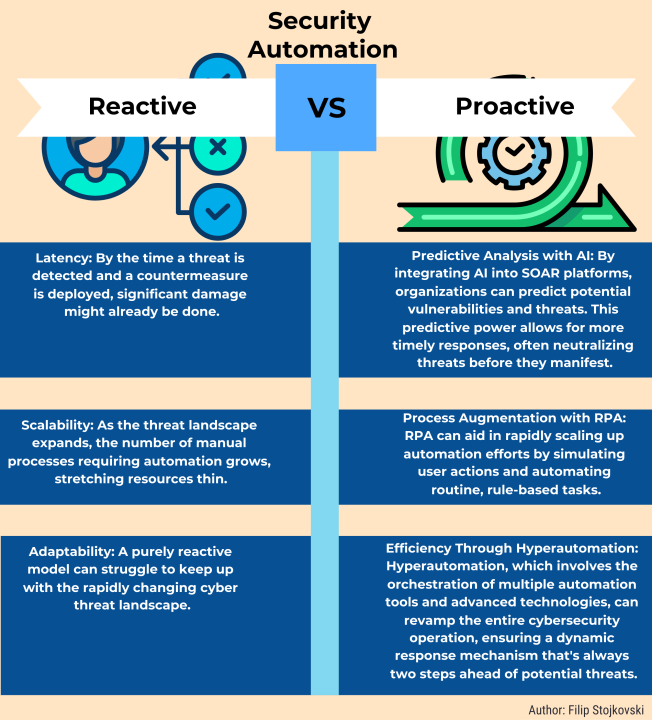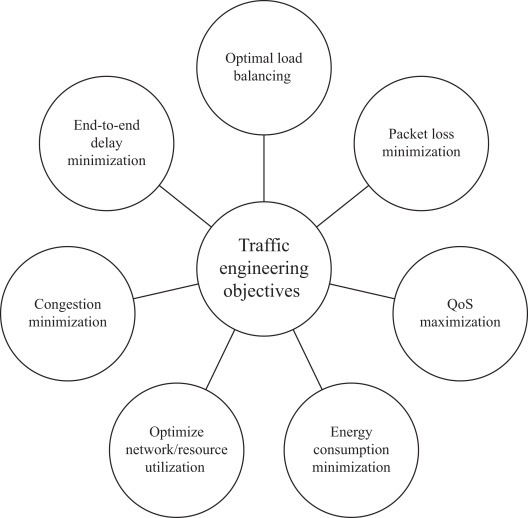
The systems analysis method for developing networks includes a crucial stage of characterizing the traffic flow patterns for new network applications. You use this information to analyze data flow patterns and select logical and physical network design solutions. Describing traffic flows is based on the flow size, the client/server protocol and the data store used to send traffic over the network. For example, a bidirectional and symmetric HTTP server/client flow might include requests from the client that are small frames (64 bytes or less) to the server that replies with a large stream of data.
Client/Server
Client/server traffic flow denotes the process of one computer program (a client) sending a request to another computer program (a server) to receive a service. In response to the client’s request, the server sends a series of messages containing data. The client-server model is a distributed application framework that divides tasks among servers and clients, which can reside in the same system or communicate through a network or the Internet. The client-server model provides several advantages, including centralized management and safeguarding data with access limits enforced by security policies.
However, it also has some disadvantages. For example, too many clients requesting data from the server at once can cause network congestion or a denial of service.
The server-client connection can only handle small amounts of traffic from several clients simultaneously. In addition, the data packets that travel between a client and server are often modified during transmission, which can result in loss of information or incomplete delivery of the data.
When you characterize client/server traffic, you can analyze the traffic with a protocol analyzer or model it with a network simulator to see what happens when a specific protocol is used. For example, you might use a network simulator to estimate the impact of a particular protocol on voice-over IP (VOIP) traffic. It will help you determine the appropriate logical and physical design solutions to meet your customer’s goals. An intrusion detection system (IDS) keeps track of network data and analyzes it for signatures resembling known assaults. When something suspicious occurs, you are notified. The flow of vehicles continues in the interim. Traffic is also observed by an intrusion prevention system (IPS). To have a better perspective, you can check out Versa Networks.
Terminal/Host
A terminal server is a computer offering end users a remote desktop service. The end user connects to a terminal server using a remote desktop protocol (RDP) client application. This software package runs on the end device and displays the contents of the session.
Typically, a terminal server includes an RDP client program that allows the end-user to connect and access the terminal server and a session manager component that keeps all sessions separate. The session manager also handles tasks such as allowing users to reconnect to their session when they accidentally close their RDP client.
Despite the decline in terminal/host traffic, networks still use terminals to support applications that require access to specialized hardware such as printers or document scanners. Moreover, thin client applications, which can behave like terminal/host applications, have become very popular.
Peer-to-Peer
Peer-to-peer (P2P) network applications enable users to share files and resources among their computers rather than to a central server. These systems can provide massive parallel computing environments, distributed storage and anonymized data routing. P2P networks originated in the late 1990s when broadband Internet access became widely available. As a result, more people began downloading music, movies and other multimedia content over the Internet. Many of these files were copied without permission from the copyright owners.
A peer-to-peer network is a decentralized model of networking in which all interconnected computers act as servers for one another by sharing files and resources, making work faster. There may be better options than peer-to-peer networks for your company. To determine the appropriate type of network for your application, characterize traffic flow and volume. A protocol analyzer or network management system records the load between important sources and destinations. Peer-to-peer networks differ from client/server and terminal/host networks in that users are responsible for storing and backing up their files, which must be accessible by other network participants. In addition, a user’s device usually runs server and client software to support file sharing and resource sharing in a peer-to-peer environment.
Distributed Computing
A network traffic flow is a series of information transfers between communicating entities. It has attributes such as direction, symmetry, routing path and routing options, number of packets, and addresses for each flow end. In a peer-to-peer environment, for example, a network administrator sets up multiple PCs on a local area network (LAN) capable of transmitting symmetrical and bidirectional data. A client on one PC connects to a server on another computer and downloads files or accesses data.
Concurrency: Distributed systems are characterized by their ability to perform computing tasks simultaneously and without using a “global clock.” They also tend to have higher availability and fault tolerance, as nodes can continue to operate without disrupting overall computation.
Transparency: A distributed system is transparent to an external programmer or end user, as the underlying components are asynchronous and don’t have a centralized architecture. It makes creating new computational systems and expanding their functionality easier.
Heterogeneity: Distributed systems have a wide range of hardware, middleware, software and operating systems. It allows for expanding computing capabilities and applications without re-architecting the entire strategy.
Aside from being used in many day-to-day applications, distributed systems are often used in research. For example, scientists use distributed systems to visualize molecular models in three dimensions, which allows them to reduce the time it takes to process X-rays and other complex images. Engineers also use distributed systems to improve product design and speed up the construction of complicated structures.